The first response
is the audition.
What 9 customers and 10 pros told us about AI-assisted initial responses.
Customer concept testing (N=9) + Pro concept testing (N=10)
The stakes
Once a customer has 2–3 viable pros,
the rest don't recover.
The RQI investigation positioned follow-up messages as the higher-leverage moment, assuming pros would have chances to recover. Customer concept testing changed that assumption.
Once a shortlist forms on the first response, lower-ranked pros have no path back — even with perfectly fine follow-ups.
"Once I had 3 viable options… I probably would not respond to the others."
The evidence base
Two studies, designed
to triangulate.
Customer side
9 participants, each chatted with 7 pros on a prototype. Each pro trained on one response archetype — 5 failure patterns, 2 success patterns — distilled from the 600-thread RQI investigation. Participants ranked pros and reasoned about their choices.
Pro side
10 pro sessions testing 3 AI-assist concepts: C1 plain draft (closest to v1 PRD scope), C2 structured draft with toggles, C3 one-tap send from leads list.
Customer study = behavioral validation of RQI archetypes. Pro study = divergent-prototype testing to find behavioral limits, not converge on a preferred UI.
What customers do when
seven pros message them.
Customer concept testing · 9 sessions
The success pattern
Acknowledgment + one bounded next step
— with two refinements.
Lightweight mirroring, not transcription.
1–3 high-signal details, varied across pros. Over-mirroring — echoing every request form field verbatim — reads as mechanical and breaks the trust signal it's meant to create.
The next step works as a question, not a statement.
A question closes the loop ("Does Tuesday at 10 work for a quick call?"); a declarative leaves the customer still deciding what to do.
Hi Sarah! I saw your request for kitchen faucet installation. You mentioned:
- Kitchen sink — single handle replacement
- Existing shut-offs in place
- Available this weekend
- Within 20 mile radius
- Budget up to $200
We are highly experienced technicians serving the greater area since 2012. We look forward to assisting you.
Transcript-style. Feels mechanical.
Hey Sarah — single-handle swap is straightforward, and weekend should work if your shut-offs hold.
Can I stop by Saturday around 10 to take a quick look?
Signal-style. Low cost to reply.
The sharpest signal
Ignoring a stated detail is disqualifying — not a trust discount, a dealbreaker.
Ignoring a stated detail is disqualifying
— not a trust discount, a dealbreaker.
"Just listen to me. If I'm telling you Saturday after 11, why are you telling me Friday and Monday?"
Chelsia flagged the same failure already visible in production — pros asking "what exactly did you want me to install" when the answer was in a photo the model couldn't see.
Segment nuance
Two customer modes,
one robust default.
Detail-oriented customers (Xuan, Melody, Barbara) treated thorough upfront questions as competence — "any pro that's going to ask about all the details first strikes me as trustworthy."
Others (NaQuia, Tanya) found the same pattern overwhelming. The middle path — lightweight mirroring + staged questions — was robust across both.
Design the default to favor the middle path. Let detail-oriented customers self-select through follow-up.
The scoreboard
Seven archetypes, three outcomes.
What pros do when we
hand them an AI draft.
Pro concept testing · 10 sessions
The pro-side headline
Most pros preferred the toggled draft.
But the toggles didn't change what they sent.
Pros described the toggles as making them feel safer sending what was already there — not as meaningfully changing the content. The mechanism is trust, not performance.
C1 · Plain draft
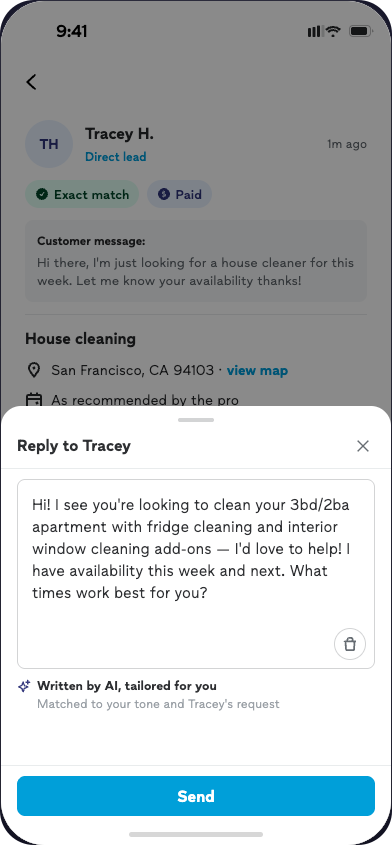
C2 · Toggled draft
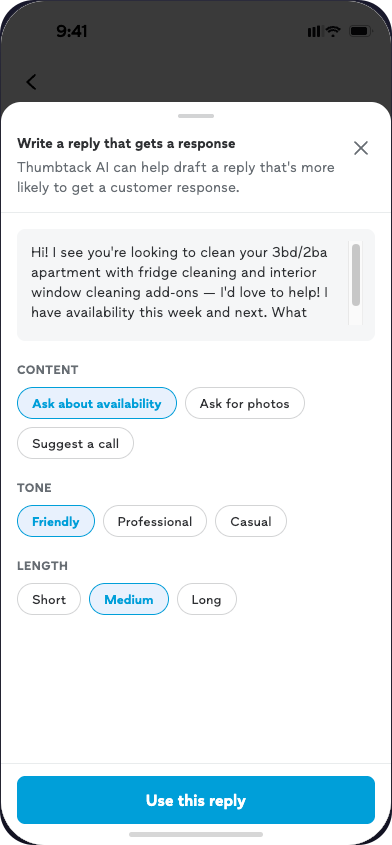
Same content. Different feeling. Different mechanism.
C2 can't ship in v1. Which means the plain draft must clear a higher bar on accuracy and voice — because pros who don't trust the output will delete it or disable the feature.
"It's a worthless tool if I can't have some input as to what it's generating."
Validating the PRD direction
Every pro said they'd always view lead details before sending.
Two overlapping reasons. Category constraints — Don, Monica, Emmanuel sell specific dates or spaces; they can't commit without checking. Universal principle — even pros without that constraint (Mark, Dan, Grace) wouldn't send cold.
"It's a trap to reply too fast."
Leads list
Lead details
The compose moment belongs here, not there.
Cross-study convergence
Both sides flagged the same failure mode.
Customer side
Bot detection is already happening. Jay wrote intentionally vague prompts because he'd detected LLM generation. Customers flagged AI through perfect grammar, em-dashes, and uniform responses across pros.
Pro side
Pros refused to adopt a tool that flattened their differentiation. "If all my competitors are clicking the same button, there is no differentiation." — Mark. Dan flagged it as a platform-level risk — if customers detect AI across pros, they lose trust in Thumbtack, not just any individual pro.
Anti-redundancy logic is currently scoped P1. The research suggests it's closer to P0 for both adoption and customer trust.
What changes
for the plan.
The moves that follow from both studies together
The operational core
Without toggles as a safety valve,
the default output has to earn trust alone.
Lightweight mirroring, not transcription.
"Single-handle swap, weekend works — can I stop by Saturday around 10?"
1–3 details. Varied across pros.
Bounded next step as a question.
"Does Tuesday at 10 work for a quick call?"
Low cognitive cost to reply.
No generic credibility boilerplate.
"We are highly experienced technicians."
Credibility comes from asking the right question.
Voice variation across pros on the same lead.
Varied length, sentence structure, which details get mirrored.
Three pros, three distinct messages.
This week's prompt work
Two prompt inputs that would close the listening gap.
Chelsia flagged that V6 outputs are still asking customers for windows they already provided. Grace flagged that multimodal query data isn't in context yet. These are the two concrete, testable hooks the research points to.
April 29 prompt finalization deadline. Both inputs are in scope if added now.
Decisions, not conclusions
Four tensions the research surfaces
but doesn't settle.
If toggles drive adoption but not content quality, the investment case is different.
If data says a question gets more replies than a call, should the draft override pro intuition?
Vary outputs → some worse ones. Uniform outputs → higher floor, lower differentiation.
Pricing transparency. v1 doesn't need to resolve it; post-MBT does.
On the NUX
What pros actually asked for was
awareness before first exposure.
Several pros — Grace, Michael, Monica, Mark — affirmed wanting advance notice when asked directly. That's what Cailee's pre-launch comms already deliver. A separate in-product NUX would be doing something additional: reinforcement at the point of use. The research didn't directly test that layer.
Advance email / push
awareness territory
Jobs tab / lead detail
optional upfunnel surface
Compose moment
trust-sensitive — don't crowd
Consolidate awareness into the GTM layer. If an in-product surface is valuable, put it upfunnel — not at compose.
A lower-confidence opinion than the rest of the doc. Flagged as such.
The close
What happens before April 29.
- Add date selections + multimodal data
- Enforce 1–3 detail mirroring, varied across pros
- Reframe next step as question
- Deprioritize generic credibility
- Decide NUX question deliberately
- Opt-out path
- GTM content leads with behavioral rationale
- Gate primary metric on visibility
- Add "disable feature" rate as adoption guardrail
Research is also refreshing the RQI codebook IRR analysis in parallel.